“Hey Thinh, we’re creating this new product that can transform the market. We want to size the potential fit for our customer base and pilot the product for a subset of clients. Can you help us understand how many clients fit into buckets A, B, C? These are the clients who are eligible to try the product. And by the way, we think that pre-retirees are the most likely clients who will benefit from this product.”
I start looking into the data elements mentioned. Hmm, what does it mean to be a pre-retiree? Maybe it’s someone who’s just a few years from retirement. But that means I need to know two things: when does retirement start and how long before that point is considered pre-retirement? From the financial advice business line that I am familiar with, it makes sense that a client should have a point that they consider themselves “retired”. But what about other business lines where we don’t have a formal relationship with the clients? Should we pick a date? What’s a fair assumption here?
After some back and forth with the product manager, she shares that a client should have retirement status, and she thinks a few years before that milestone is roughly what “pre-retirement” means. She’s not sure what data fields capture this, but I’m the analyst, it’s my job to find out.
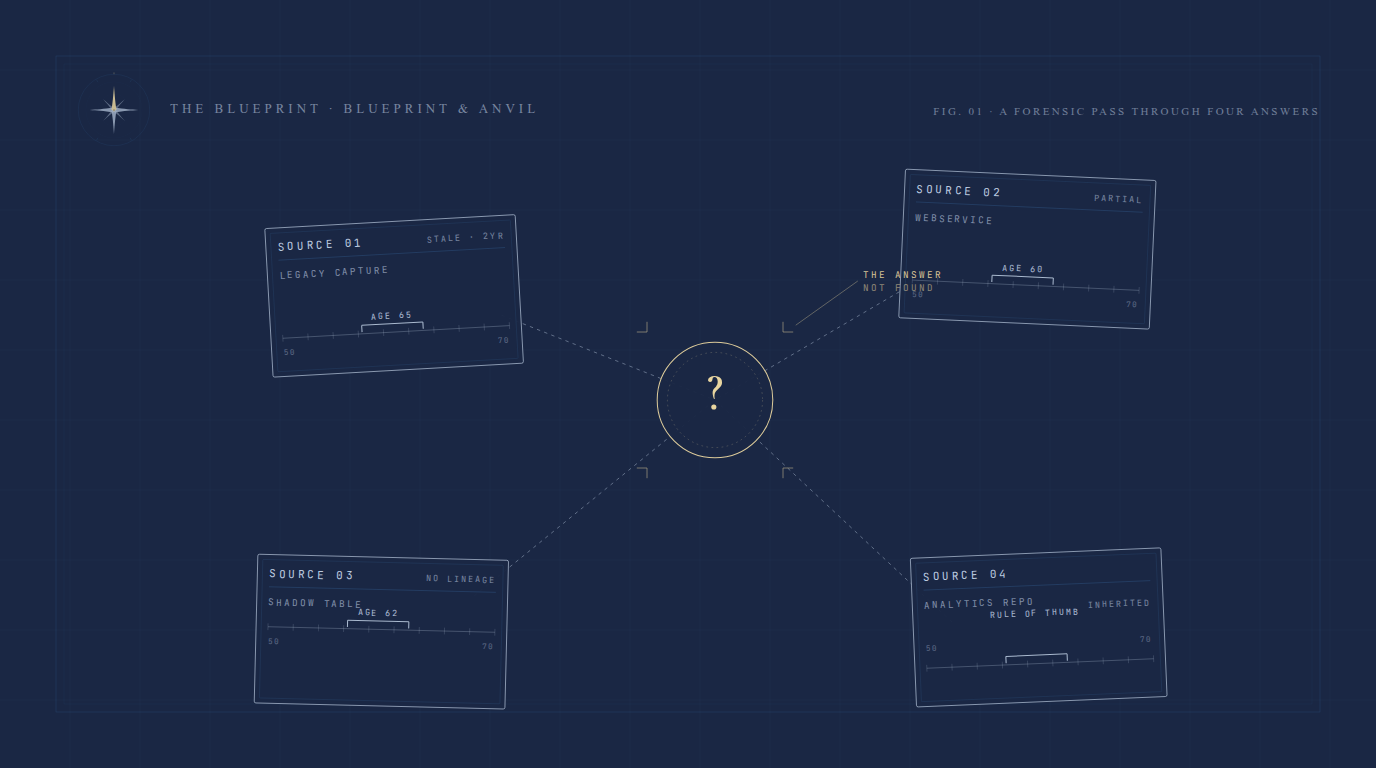
So the search begins. I look into the internal wiki, rummage through the corporation’s chat threads, and peruse the enterprise data management system. Lots of info here. Apparently a process already captures this concept. This is great! Let me look at that data. These examples make sense. Good. Hmm, wait, why are there so many missing observations? Oops, so the data was last updated two years ago. This is a legacy process. No wonder that the data is stale. No good.
Alright, there must be something more here. I keep digging and find a jumble of competing sources. There is a webservice that handles retirement status, but only for a newer business process: more current data but no legacy. There is another different data table with more complete data, but it contains some discrepancies with the legacy source, and there’s no code anywhere to review. The last source is from an analytics team, with links to documentation and a code repository. For the next hour or so, I slog through the poorly formatted code, and find that they combine logic from the legacy data, the rule of thumb mentioned by the product manager, and a default retirement age for clients not in the current business line.
By the end of the day, I have four different sources, four slightly different definitions, and more questions than when I started. This has now taken a whole day, so I’ll resume the investigation tomorrow.
A new day, a fresher mind. I reach out to a couple of folks whose names I find in the sources as well as from talking to my teammates who have been here longer. It takes a few tries since some of the contacts are no longer with the company. The earliest meetings I can find are a few days from now, so I’ll move on to other data elements in the original request.
But then something hits me, and I take a pause.
The last two sources I found - each one was someone else’s answer. Another analyst, another time, another version of the same question. They dug through whatever existed before them, hit the same walls, and wrote down their best guess. I’m about to do the same thing they did.
You know how horror movies usually go. The main character survives something terrible, sees visions, and finds remnants of some violent past, realizing that they are trapped in the same cycle.
I have been down this road too many times. The pattern is real. It’s not just a data findability problem. The knowledge is social (living in people’s heads), contextual (depends on use case), and often undocumented by default.
I spend hours finding a number, but at the end, what I really have is not an answer - it’s a guess with the messy context that only I can see.
Have you been here before?